
This post “How can we adjust to Working Agile with Cloud-based Microservices in CI/CD” is my software testing degree project written during the last course of a software test engineer education. All information from the thesis is not included and some text is changed. The original document is available as a pdf Link to pdf here This is part 3 of 5.
This post will be pretty lengthy, so might be a good idea to refill that coffee cup before reading. ![]()
Themes Identified
Based upon the answers from respondents I will in this part list the themes found in the interviews. Since the respondents was given the option to answer freely from their own perspectives the answers varied a lot. Therefor I will list the themes I found relevant to the specific topic.
1. Below are the themes identified on the topic of problems test engineers are facing. Here I asked about their thoughts of over-all problems and based on their answer some follow up questions were made for clarity. Also, to assure that the answer was from a test role perspective and not developer or organization based.
Production, Staging and testing environment differences.
One topic mentioned to be a problem and something that could cause more problem later was the overconfidence in staging environment. Explained with the example that there still is differences and the environments is not close enough to rely upon. If testing is made in a test or stage environment, we can´t know for sure that the application will behave the same in production.
Access
This was explained to be a problem working with microservice in any environment not just an agile work approach. That the testing is handed over to testers without reliable and accurate documentation, a tester can´t know all the ways this specific application and its services works without getting access to it.
Knowledge
This is a topic being repeated in almost every discussion, the difficulty to find the right person responsible. This includes to find the person who can explain certain features or architecture, to get access to software needed. Also, knowledge between different teams, the teams might work only on one part of an application or feature. If tests are being done over the team structure it might cause a bottleneck and delay testing.
End-to-End Testing
There are several problems mentioned under the topic of end-to-end testing. End-to-end testing is a method used in most projects and is seen to be the ultimate answer of the applications health. The problem mentioned is that end-to-end testing do not tell us about the interaction between containers, not between services or databases. It is also known to be flaky, to fail to produce reliable data.
Tool Sprawl
From the topic of knowledge this is one theme that I decided is important enough to set in its own theme. With agile the teams decide tools, frameworks etc. within the team, of course within certain limits. Different teams have different priorities and preferences, and this easily cause the summary of tools used to raise in numbers. It becomes difficult to overview, to find the correct software used and, in the end, to integrate data from a high amount of software.
2. In this section the topic was about best practices. First, I asked this question in an abstract direction to let the participants answer based on their own knowledge or what they would wish for. I realized my mistake here as the answers went in a lot of different directions and not focused on test coverage. This made me go back with a follow up question that involved type of testing and priority of those.
Performance Testing, Stress
Stress testing were one of the test techniques mentioned often as a best approach. The reasons for why we should do stress testing varied in the answers, but theme identified were to stress test the overall system. The approach mentioned was based on if we have available data from load testing. If we have access, we should automatically generate test data from that model and set about 10% greater. If we don´t have data available, the approach should be focused on the interconnected systems individually. Create a diagram of the system, find if we have critical areas in the service call chain, and then do high level stress tests on each individually. One important note was that we need to make sure there is a deploy available to manage potential downtime.
Test Automation, Contract Testing
To resolve the end-to-end testing problem mentioned above contract testing is mentioned. The arguments of why this is a best practice theme were not only about solving the end-to-end problems. It was mentioned as a method to gain control of the interaction between services, by isolating each service and with test doubles check that requests and responses share the same understanding documented in their contract. Mostly a provider-driven approach was discussed, an argument for this was that it covered evaluating the backend functionality and was seen as a more stable approach than consumer-driven contract testing. If an application was tested with contract testing it ensured stability earlier in the testing process and limited the need for end-to-end testing.
Logging
To reach full testability and observability logging were a theme that was included in the topic. Although, even with the importance of logging this topic also highlighted that most applications today are setup with good throughout logging data. It was more so the lack of knowledge how to collect the right data from unorganized logging systems.
Monitoring, Distributed Tracing
In the theme of logging, monitoring was another topic mentioned by mostly all participants. The type of monitoring that was seen as a best approach depended upon the participants background and specialization. The people with a profession within cyber security it was clear that this was a priority and both distributed tracing and service mesh. The importance of having abstracting layers (service-mesh) to take care of service-to-service communications, and to follow the request flow with distributed tracing. Other professions also mentioned monitoring and observability as one of the top best practice themes. That with monitoring we gain control to see issues in real-time and can easily detect where in application the problem occurs.
3.This question was asked to get an understanding how test engineers experience level of priority when it comes to testing in the development lifecycle. To see if there could be differences depending upon their role, company and perspective based upon the other topics discussed.
Test Automation
Test Automation was mentioned to be seen as a priority. To implement automated tests instead of manual testing. Here unit testing was discussed, developers might implement these tests and see them as enough to verify the application as tested.
Push to Prod
One participant said it like this: “easy to fall into the trap of push to prod”. The impression that if there is good monitoring in production things should go fast and easiest solution is to push directly to prod without testing. In the same category it is mentioned that with minor changes it is easy to justify skipping testing, since it is in fact just a minor change.
Developer perspective was another term used, said in the context of CD, testing being overlooked in favor of fast deployment.
Application Coverage
In this section I have taken the themes identified above and studied the different topics closer. I also continued my study of the thesis topic to make sure I cover most parts of what type of testing can be done within microservices.
I used this architecture diagram as a reference to see paths to cover and what could be important.
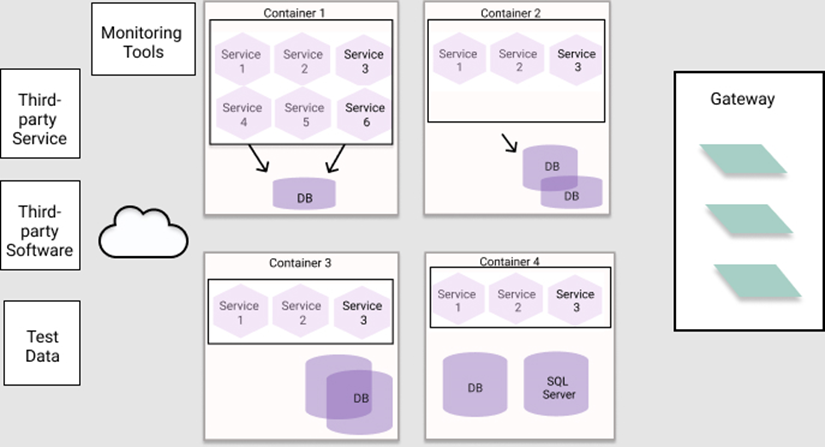
In this we can investigate some type of testing and follow if it covers all parts of the application. A note here that I will not investigate TDD or any of that type of testing, this is a decision based upon two reasons. The time limit of this thesis and the fact that the research I have done do not show test driven development as a common solution to implement to an already existing application.
Unit Testing
To start testing on a bottom level to ensure that each function within a service works correct, we use unit testing. Here we write the tests to observe the behavior of modules and can easily see changes in their state and find problems in the very first stage of implementation. It only focuses and gives us the result of that specific function. Even if unit tests mostly are done by developers and not handed over to a test engineer, I find it important to include it in this thesis.
Integration Test
In my research I came across Integration testing in most discussions and studies of microservices and agile work approach, therefore I looked closer at the topic.
After unit tests has confirmed the functionality of separate units it is needed to check the interaction of different units. On this second level of testing more of the application needs to be up running to determine that the interaction is correct. There are many parts and ways to test the integration, we have:
- Integration between different services
- Connection to databases
- Connection to other external sub-systems
- Higher to lower or Lower to higher level testing
- API testing
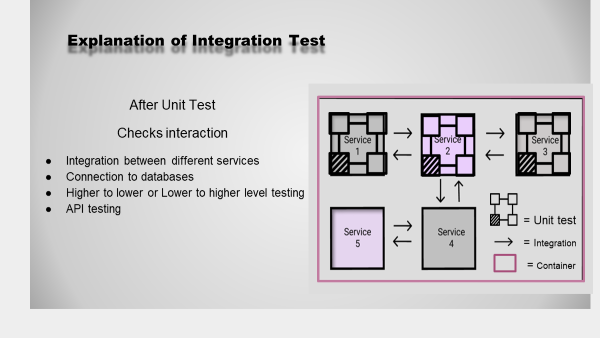
Synthetic Monitoring
To identify issues in the application before it reaches the end-user synthetic monitoring can be used. There are other terms used for this technique, in this thesis I have decided to only use the term synthetic monitoring with the opinion that it is a part of the testing process.
Automated, scriptable tools are used to perform synthetic monitoring. It is possible to cover most of an application’s different areas with this monitoring method. I investigated some of the methods mentioned the most in my study:
- Ping test – check reachability of the application, ensure it is available to users.
- API tests – To monitor the applications API endpoints in both single and multiple-step endpoint requests.
- Step or Simulation tests – Here we use test doubles to simulate the steps taken by a user in the process of using our application and different functions.
- SSL Certificate monitoring – Ensure the security of the application by monitoring the validity, encrypted connection and up-to-date of the certificate.
CDC, Consumer-Driven Contract Testing
In the section 5.4.7 Test Automation, Contract Testing above it is mentioned that the discussions mostly were directed towards Provider-Driven Contract testing. To see the functionality from the consumer requests and to ensure the provider understands the requests coming there is consumer-driven contract testing.
Here I decided to look further into the concept and write a small application to get a better understanding of coverage possibilities. In my analysis of the contract testing topic, I came across a team of testers and developers that was looking into this topic. The discussion was as mentioned directed towards provider-driven and backend, and it was done with the software Pact. Therefore, I decided to use the very same in my experiential research of CDC testing.
Pact is a code-first tool for contract testing. It is used for both Provider and Consumer-driven Contract testing. There is also Pactflow, which integrate with Pact but is used in the deploy pipeline as an automated contact test.
To explain contract testing this diagram shows the flow:
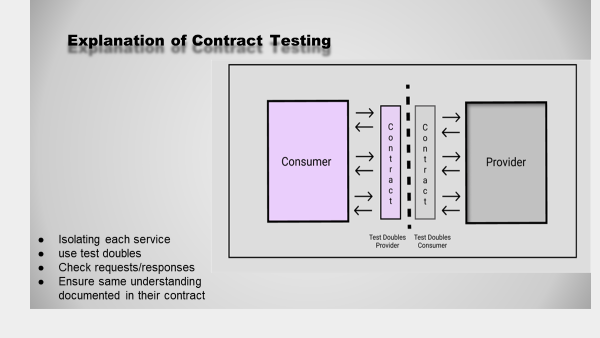
As mentioned, I focused on the left part, where the Consumer sends requests, as seen in the diagram the request is sent to a provider contract with test doubles.
In my application I decided to build an Android application using Kotlin, the application is simply just comparing a To-do list. The test written is focusing on the function communication and not user interface behavior. The test is directed towards a test double API. Since it is possible to write these tests on a unit level it is a direct communication between consumer and provider as shown in the example above. I compared this with how we would need to set up integration test to make sure to cover similar field. This diagram shows the flow for integration test:
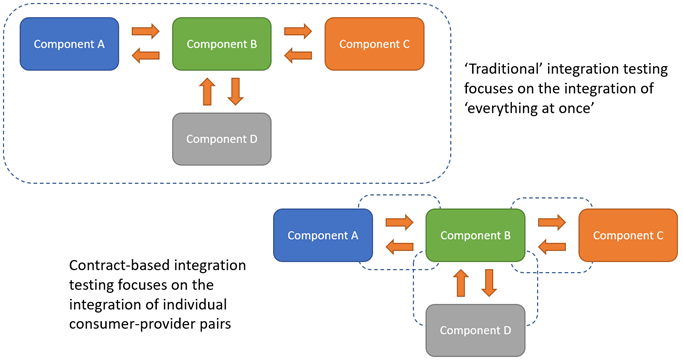
By Bas Dijkstra
The post Bas wrote about this subject is really good and I recommend you to read it if you want to learn more. Here is a link to Bas post about the subject. Link to blog post
As seen in the diagram there is requests sent and received with focus on the full service instead of just one service at the time.
In the next post we will cover my analysis of the themes found.
Links to previous posts in this series can be found here:
Link to part 1
Link to part 2